Mass Customisation, if you have not experienced it, is the ability to tailor a retail product to your own tastes and have it manufactured to order. Many well known brands such as Reebok and The North Face are now offering configurable products to their customers and it is catching on in many industries, not only apparel but also furniture, jewellery, automotive and many more.
To enable Mass Customisation two key problems had to be solved. First to be solved was the manufacturing processes. How do you make a customised product quickly enough and for a low enough cost to offer it in the same way as mass produced products? This has been an area of considerable research and development in recent years and brands have already started to roll out successful examples of this type of manufacturing.

Photorealistic Rendering of Configurable Products, Courtesy of Fluid Retail for Wild Things Design (Rendered with RealityServer)
The second problem, and the one of more interest here, is how to show the customers what their made to order product will actually look like. Studies have shown that customers are far more likely to purchase products online when the picture shown to them is of the actual product they will be buying. In most cases, a mass customised product won’t even exist until the customer has placed their order and it has been made, so how was this problem solved?
Photorealistic rendering. It has been used for feature films, television commercials, architectural design, product design and any number of applications that require presentation of something that doesn’t exist. Today, it is possible to produce photorealistic renderings that are indistinguishable from a photograph and in many cases at a cost lower than obtaining professional photography.

One of these images is a photo and one is a rendering, can you tell which is which? Courtesy of NVIDIA.
Let’s dive deeper into the different ways rendering can help increase sales conversion for configurable by improving image presentation quality of mass customised products.
We are focusing here on using computer generated imagery rather than photography for customisable products. Photography can be feasible for applications with a very limited number of combinations or situations where a neutral product can be photographed, masked and then re-coloured. However the effort and cost involved with this increases exponentially as the number of options offered to the customer increases. So let’s be clear at the outset that we are always referring to computer generated imagery here.
Detailed 3D models are now readily available as a direct by-product of the design and production processes associated with almost all modern products. Data from CAD/CAM tools can be readily utilised as a basis for the creation of accurate and highly realistic product imagery. This does not just apply to products that are engineered. Using the right workflow, 2D cutting patterns from traditional garment manufacturing can be automatically turned into 3D models. Many other industries are also adopting techniques that are making 3D models the new norm rather than the exception.
While we are focusing on customisable products here much of what is being talked about also applies to more conventional products and the same techniques can be applied there.
Hopefully not everyone reading this is a computer graphics expert as these technologies have broad applicability. If you are not familiar with computer graphics then here are a few definitions to help frame things for you. Skip over this bit if you know your stuff.
Rendering is the act of taking a 3D scene description, containing information about geometry, materials, textures, lighting, camera and product configuration and producing a conventional 2D image that can be viewed on a screen. This is a very simplified definition since many rendering techniques produce much more than a simple 2D image but for the applications considered here this is sufficient.

Left: 3D Geometry, Materials and Lighting Data, Right: Photorealistic Rendered Image. Photorealistic 3D rendering takes multiple source data, much of which is created during product design and generates an image from this data.
There are a huge number of rendering techniques available which produce many different results. Some are completely photorealistic while others may use compromises to get faster results with a lower level of quality. Some can even produce cartoon like results or be stylised to obtain a particular look and feel. We will focus mainly on photorealistic rendering here but this is by no means the only way to render.
The term rendering can be confusing today since it is often used in other areas, for example, a web browser is said to be rendering a website, which of course does not refer to the type of 3D rendering discussed here.
Compositing is the act of taking two or more 2D images and combining them to produce another image containing some form of combination of those images. For representing configurable products this would usually mean fragments of a product which can be individually configured are kept in separate images and combined together to make a complete image.

Left: Image Fragments of Configurable Parts, Right: Composited Result. Compositing takes images as input rather than 3D information and combines these in some way to create a complete final image.
To facilitate compositing often the 2D images will have additional information in them such as depth, alpha and label channels which can be used during the compositing process. These channels can be produced as part of the 3D rendering process and when this type of data is used we will often refer to it as 2.5D compositing to make note of the fact that some 3D information is being used.
Compositing can be used both with computer generated images and photography however for photography this typically involves manually masking out areas of interest or complex capture techniques using markers or specifically coloured materials.
Before outlining some techniques that can be used to solve the image generation problems of mass customisation, I want to give you a flavour for the scale of the issue. Let’s take a real world example, the Men’s Custom Denali Jacket by The North Face. Here’s what you can configure.
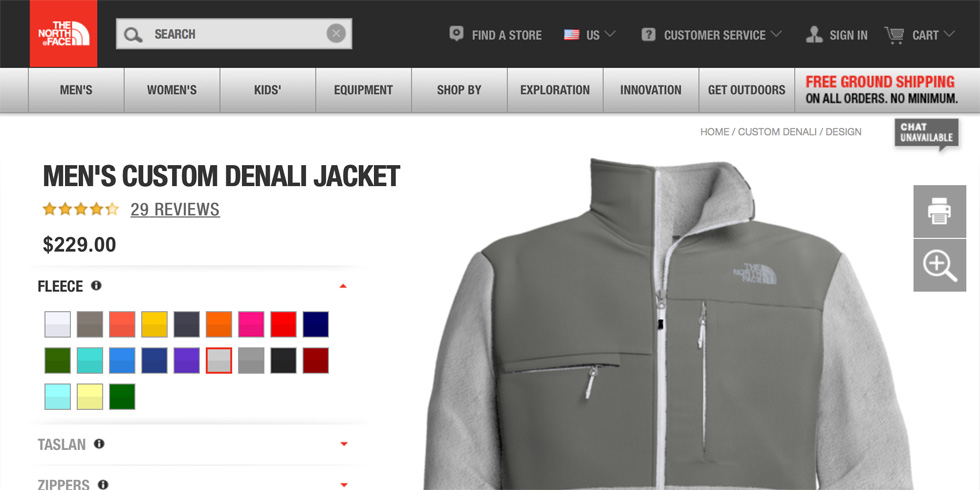
Men’s Denali Jacket by The North Face – Customised Just for You (Rendered with RealityServer)
Now this is a relatively simple example and at the lower end of what is possible, however if you multiply that out you still have a lot of possible configurations.
21 × 14 × 17 × 17 × 23 = 1,954,218
That might not sound like a simple example but this product doesn’t offer pattern changes or different geometries and the total number of combinations is actually relatively low. It is also just one product, most brands offer many different customisable products.
The North Face experience was created by one of our great customers, Fluid Inc using our RealityServer technology for image generation.
In the Go Big or Go Home spirit let’s take a look at just one of the 420 products we helped Boathouse Sports generate configurable image content for. This is where it gets a bit crazy, for the Flight Ice Hockey Jersey you can configure the following basic options.
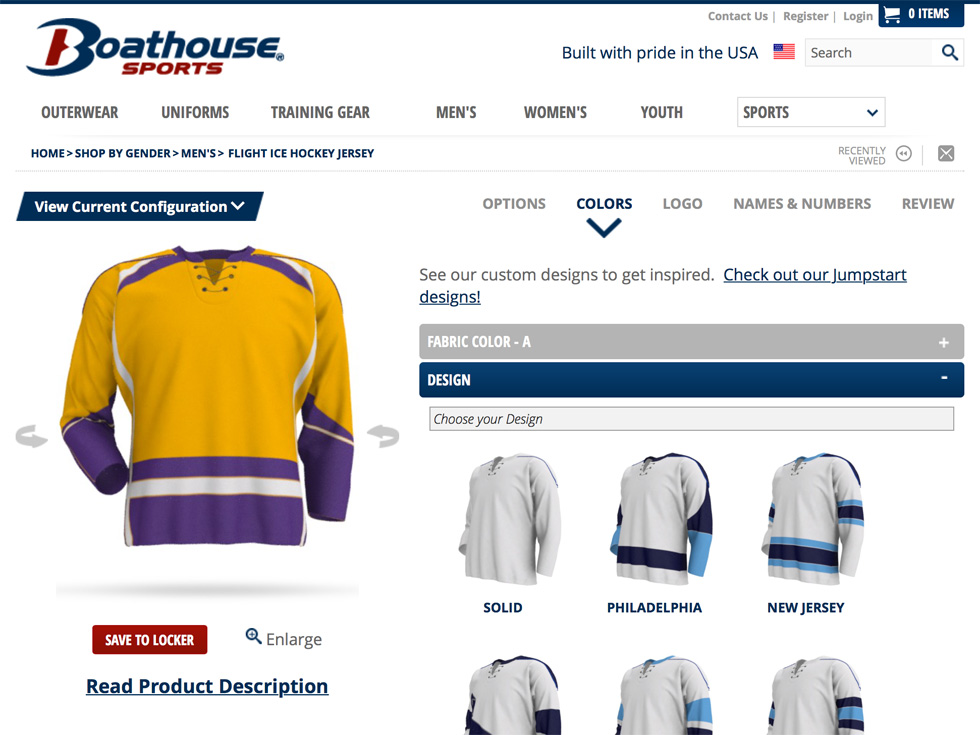
Boathouse Sports Flight Ice Hockey Jersey – The Pre-generated Configuration Engines Worst Nightmare
We’re going to do a few calculations now based on this example just to demonstrate how quickly the number of combinations can explode. Feel free to skip to the huge number at the end if you just want the answer.
I say basic options since after you select these options you can then add embellishments in ten different locations on the garment which takes things even further and in some cases results in an infinite number of combinations since the customer can upload their own material. We’ll just stick to the basic options though. So, for everything that we can configure a colour on we can pick either from 30 solid colours or from the patterns which use multiple colours (the number varies between patterns). So the total number of colours and patterns available is calculated like this (the powers are the number of colours in each of the available patterns).
304 + 305 + 302 + 304 + 304 + 303 + 302 + 303 + 302 + 303 + 303 + 303 + 302 + 302 + 302 + 303 + 303 + 302 + 303 + 302 + 303 + 302 + 304 + 302 + 302 + 303 + 303 + 302 + 303 + 302 + 304 + 302 + 302 + 30 = 28,687,530
Now for each design option we have a number of colour areas we can assign one of these colours to. So to calculate that we do the following (the powers are the number of colour areas in each design).
286875301 + 286875303 + 286875303 + 286875303 + 286875303 + 286875303 + 286875303 + 286875303 + 286875303 + 286875304 + 286875302 + 286875303 + 286875303 + 286875303 + 286875302 + 286875304 + 286875303 + 286875303 + 286875303 + 286875303 + 286875304 + 286875303 + 286875302 + 286875304 + 286875303 + 286875303 + 286875304 = 3,386,434,555,078,810,357,761,753,226,230
Are we there yet? Wait, we still need to multiply in those simple options from the start, so finally we arrive at the following for the total number of basic combinations.
3,386,434,555,078,810,357,761,753,226,230 × 17 × 3 = 172,708,162,309,019,328,245,849,414,537,730
So, for those who like to hear the words, here is the number.
One hundred seventy-two nonillion, seven hundred eight octillion, one hundred sixty-two septillion, three hundred nine sextillion, nineteen quintillion, three hundred twenty-eight quadrillion, two hundred forty-five trillion, eight hundred forty-nine billion, four hundred fourteen million, five hundred thirty-seven thousand, seven hundred thirty
Now of course, there is no way that all of these will ever be chosen by any customer, however how can you know which to generate in advance? The short answer is that you can’t and pre-generating all of these images, even with a render time of only 5 seconds and all of the computer resources in the world today it would still take longer than the age of the universe to create all of the needed images. And you thought cryptography was hard.
Keep in mind that this is also just for a single view of a single product, the production site for Boathouse hosts 420 products and each has six available views and my example was by no means the most complex product. This wide range in combinations is one reason that when we talk to customers we never talk about a single way to do things. Let’s take a look at some of the options we to solve this problem.
Regardless of the technique used, the end result must be a complete image representing the product in the correct configuration as selected by the customer. There are a lot of different ways to approach this even when using computer generated imagery exclusively and each method has its own advantages and disadvantages. It is definitely not a one size fits all problem.
Let’s run through some of the different approaches that are available with today’s technology. Later we will provide a tool to help you choose between these options based on your requirements and see what might best fit your needs.
The simplest approach is always to just pre-generate all of the imagery that you will need in advance and just deliver the appropriate image for a given configuration. This requires very little development and more or less just a nice naming convention to allow you to load the right image.
This approach can be practical when the total number of configurations available on the order of 50,000 or less. If you make some assumptions about how long each image will take to render and calculate how many combinations you need then you can get an idea for how much time you might need to wait to get it all done.
Even when using pre-generated imagery you are still going to want to try and automate the rendering process (unless you have a truly small number of combinations, say less than 100). You have a few options there, one approach could be to build some scripting and tools around an existing renderer which has a command line version, mental ray, Renderman or Vray for example.
Another option (one which of course I am biased towards) is to use RealityServer and its built in NVIDIA Iray renderer through the simple JSON-RPC API to build out an automated rendering solution. The big advantage of this approach is that it can load complex data and then keep it loaded while manipulating it and rendering out new images. This saves the overhead of unloading and reloading data that occurs in more traditional production rendering tools.
Let’s summarise some of the key points here.
Probably the most popular approach used today for configurable products is compositing. Here, rather than pre-generating all possible combinations you generate individual elements which have been separated based on their configurability. These elements can then be combined in different ways to make configurations.
The goal with composited imagery is to break down the problem into pieces where the combinatorics of each piece works out small enough to handle with pre-computation. It’s essentially a divide and conquer approach and basically it just moves the line where the number of combinations is practical to pre-compute. To understand why this works we’ll take a look at a typical example.
Let’s take Denali jacket mentioned earlier. If we brute force it we will have to generate the following quantity of images.
21 × 14 × 17 × 17 × 23 = 1,954,218 images
With plentiful hardware, lots of time and a reasonable rendering time this might be practical to do in a couple of months. What does it look like however if we take a compositing approach.
21 + 14 + 17 + 17 + 23 + 1 = 93 images
The +1 at the end is for the image containing the static elements which don’t change between configurations. Now these are not complete images, they are fragments and you need a system to combine them together later, either on the server or in the browser. You can see however that this approach can significantly reduce the number of images needed.
When you only need to make colour changes and not textures or patterns you may even be able to tint the images on the fly in which case you could just produce a single image for each piece or a label mask for tinting, cutting the required images even further.
The above is assuming that each of the combinations has no effect on the others, for example it is assumed that changing the colour of the sleeve has no effect on the front panels of the jacket. In reality this is not the case, indirect illumination from one piece will affect the other however in many cases customers consider this simplification an acceptable compromise.

Left: Complete Illumination, Right: Indirect Illumination Only. Note the subtle but important contribution the strong yellow midsole makes to the rest of the shoe. While not noticeable on the left image when absent it can look very wrong, particularly with strong colours.
Compositing is usually done by masking out sections of the image, either with an alpha channel or an explicit masking buffer. There are some subtleties here that are often overlooked such as pre-multiplied alpha, colour spaces and compositing order and even when implemented correctly, traditional compositing can lead to edge artifacts around objects.
Compositing can get even trickier when you have geometry changes and can only really help there if you start taking 2.5D approaches and compositing with depth taken into account. This can work but is difficult to do in the browser and can result in significant aliasing problems (jaggies and staircases). A particularly difficult case is where a configurable object is both in front of and behind another.

Left: Jacket Without Hood, Right: Jacket With Hood. Example of a geometry change which can be difficult to handle with a pure compositing approach. Complex and error prone depth based compositing would be required.
Transparent objects pose an even bigger problem, particularly if their transparency can be varied since they will potentially reveal objects that were not originally included and so give incorrect results. There are tricks that can be used for this as well, however, they have significant limitations.
When geometry changes are not important there are two powerful, recent techniques that can be used to get better results: Deep Compositing and Light Path Expressions. Deep Compositing was pioneered for the film industry and works by storing additional information during rendering instead of just the colour of the closest object in a pixel. This allows for interesting depth based effects and modifications to content after rendering.
Light Path Expressions (LPEs), available in RealityServer 4.1 or above were introduced in Iray 2014 and allow you to render not only different components of the lighting but also specific objects. In our implementation we can currently render up to 7 components in a single rendering pass and output these to separate image buffers, each containing the contribution of a single object.
The great property of LPEs is that to composite them you simply add the contributions together, literally A+B to get the final result. There are some caveats, such as the need to do this all in a linear colour space, but with those aspects taken care of compositing becomes extremely simple and avoids edge artifacts that alpha compositing or masking can introduce.

Left: Complete Image, Center Left: Diffuse Component, Center Right: Reflection Component, Right: Transparency Component. Using Light Path Expressions in NVIDIA Iray to separate various elements of an image can be extremely useful for configuration scenarios.
For the right use cases compositing can be a great option, you just need to make sure that the failure cases are not going to be critical for you and that you are not doing too much geometry configuration. Here’s a quick summary.
While we work with both Pre-generated and Composited Imagery, Dynamic On-demand Imagery is really where we have specialised and it has become a requirement for many of our customers due to the increasing level of customisation they are offering.
In this approach no pre-generation is performed at all. All 3D content, geometry, textures, materials and lighting reside on servers running rendering software such as our RealityServer platform. When a configuration is selected the rendering software dynamically renders the required image and sends it to the customer.
Using this approach each configuration is rendered entirely from scratch and so it can account for all possible configurations without the need for complex compositing or extensive pre-generation of content. Often a web application will sit between the rendering software and the customer to manipulate or manage the generated images in some way.
While it would be feasible to take an off the shelf renderer such as mental ray and call it from a web server, this would have a lot of potential security issues and involve some significant development. Furthermore renderers like mental ray are not licensed for this type of use. RealityServer is much more specialised and licensed specifically for these types of applications.
Another key consideration in selecting a rendering platform for this type of application is how quickly it can respond to new requests and whether it can retain, in memory, a database of configuration elements to be assembled just prior to rendering. Of course rendering performance is also a major concern once you come to full on-demand image generation since the customer will need to wait for the render to complete to see their results.
Traditionally, offline renderers take many minutes or even hours to generate high quality images. Modern renderers exploiting GPU hardware such as that offered by NVIDIA are able to generate results much more quickly and are designed for high throughput applications. Due to the huge number of combinations required, the Boathouse Sports website discussed earlier utilises dynamic on-demand image generation. The majority of images are rendered in around 4-6 seconds using RealityServer.
How about some quick bullet points to recap.
This approach extends Dynamic On-demand Imagery to include a caching mechanism to ensure that no particular configuration is rendered more than once. This has the effect of decreasing server-load for the rendering servers and improving response time for customers when requesting previously requested configurations.
In many configurators there is a high degree of probability that different customers will select the same configurations in a number of cases. Once a customer selects a configuration the server will dynamically generate not only the content needed immediately, but other content needed for the same configuration, for example, additional views, zoom views and other items.
All content produced in the system can be stored in a cache and additionally in a CDN (Content Distribution Network) for improved performance and geographic coverage. When a customer selects a configuration that has already been requested it would be retrieved from the cache instead of being rendered again.
This one is pretty simple to summarise.
In recent years an increasing number of companies have begun using 3D directly in the browser with technologies such as WebGL, Three.js and Unity3D. This is a compelling area of development since it pushes the 3D hardware requirement to the end user and removes the need for brands to host this capability on their customer’s behalf. There are however some issues.
Pushing the hardware requirements to the end-user is a good thing, so long as they have the hardware. It’s getting easier to assume this with recent iPads and Android devices having very capable 3D hardware in addition to most laptops and desktops now having enough grunt to do some level of 3D. Sites like SketchFab and platforms like PlayCanvas can now exist thanks to WebGL support and 3D hardware becoming more ubiquitous.
Looking at projects we have done with server-side rendering, however, the data sets pose a significant problem. Many comprise hundreds of megabytes of data (even when compressed) and millions of polygons (one of the fundamental measures of complexity that needs to be considered when using rendering technologies such as WebGL). These factors mean that a lot of information needs to be moved to the client side before the first image can be made and a lot of 3D processing power is needed on the client side.
This raises an important metric we often deal with and like to call Time to First Image which defines the time it takes from the first moment a particular images is requested to the moment it is returned and displayed. This is important for all image generation methods but becomes a significant factor with client side 3D because images cannot be generated until the data is transferred to the client.
Client side 3D technologies such as WebGL are also limited in the quality of the images they can produce, particularly if lighting cannot be pre-computed. With the right tools and techniques you can get some very impressive content with WebGL but is can’t approach the quality that can be achieved with a real photorealistic rendering engine such as Iray. For many applications, however, it might be good enough.
Adoption of WebGL is still not quite widespread enough for sellers of mainstream products to rely on but that day would seem to be coming very soon, particularly with this being exposed in iOS 8. There is a lot more green on the Can I Use page for WebGL than their used to be, so if you are targeting only modern browsers it might now be an option. Unity 5 will also include a WebGL backend which could make it viable for authoring.
That’s a long title but basically what we do here is combine client-side 3D technologies like WebGL with a server-side image generation system like RealityServer. The idea is to try and get a ‘best of both worlds’ approach, where interactivity is high but high quality can also be achieved when needed.
Typically deploying this approach would involve using two sets of 3D content, one which has been dramatically simplified and compressed for WebGL and the other full detail content used for high quality server-side rendering. These would be two versions of the same content and be setup with the same structure and positioning.
When the user initially visits the site, the low detail WebGL model would be downloaded and viewed, allowing configuration options and views to be selected easily and providing some level of feedback even if the quality isn’t very high. Once configured the customer could either specifically request a high quality version of the rendering, or alternatively this could be requested automatically when the user stops changing the configuration.
While I may appear to favour on demand image generation, in fact we have used all of the techniques described above at one point or another depending on the specific requirements of the project. It is important to think about what you need to achieve now, as well as what requirements might arise as you add new products or more configuration options to existing products.
So how do you make a decision? To get you started we have created a calculator into which you can input the importance of various aspects of the system and get a rating for each of the techniques discussed above. Get in touch with us if you are interested in the logic behind this calculator which was created based on our experience across many projects.
You can move the sliders in the calculator and watch the relative suitability of each technique change. Now, don’t just slide everything over to the right, you really need to think about what things are critical for your specific application and what aspects you can be more flexible with.
If you need an image generation solution for mass customisation but don’t fancy building it yourself, then don’t hesitate to get in touch with us. We have helped many companies implement image generation for mass customisation and are happy to chat about what might work for you. We think RealityServer is an ideal match for these applications with its easy to access JSON-RPC API and state of the art NVIDIA Iray rendering technology. RealityServer is already powering many top brands’ websites, so there is a good chance you have already seen images created with our platform and not even realised it.
Paul Arden has worked in the Computer Graphics industry for over 20 years, co-founding the architectural visualisation practice Luminova out of university before moving to mental images and NVIDIA to manage the Cloud-based rendering solution, RealityServer, now managed by migenius where Paul serves as CEO.